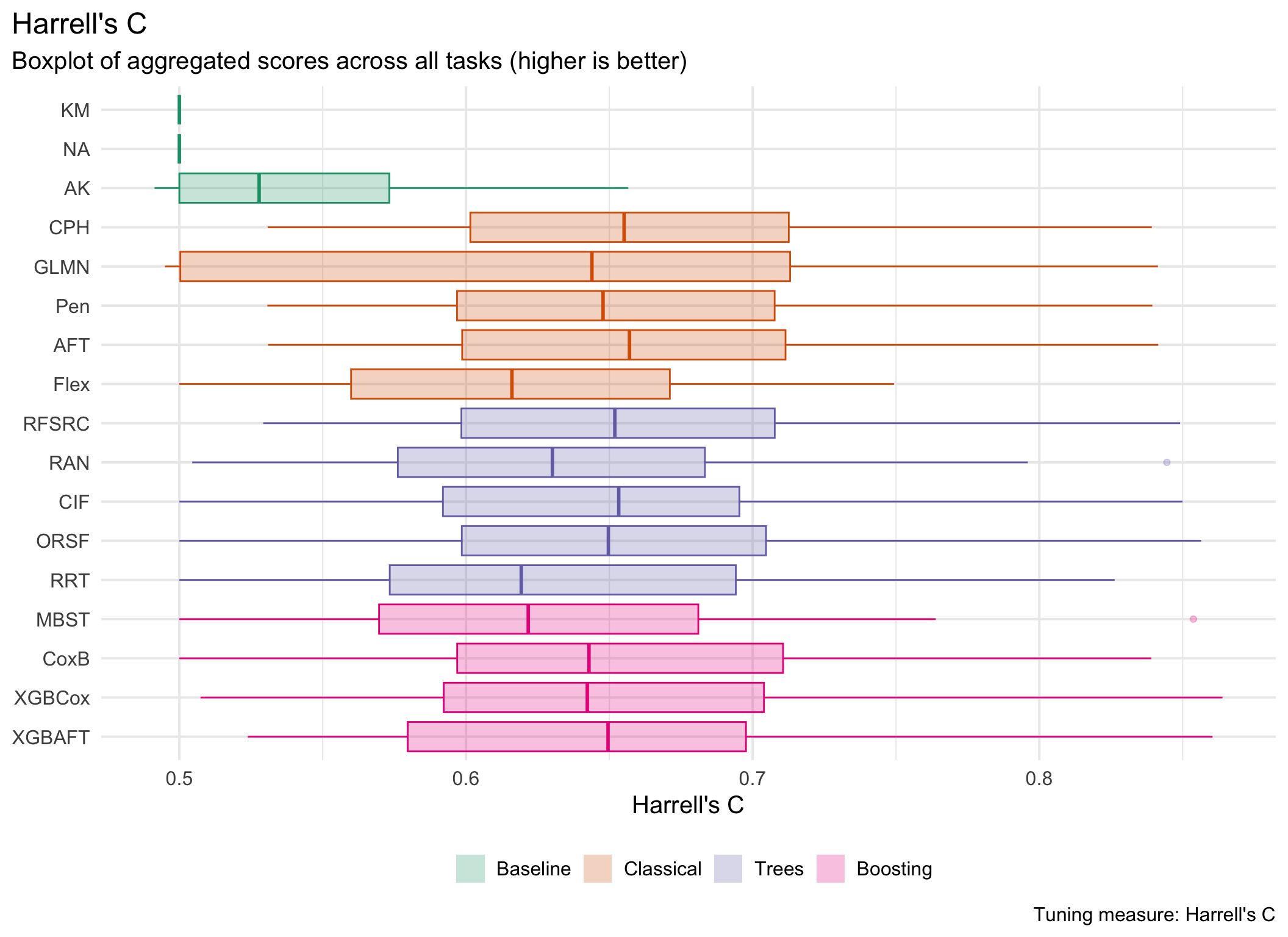
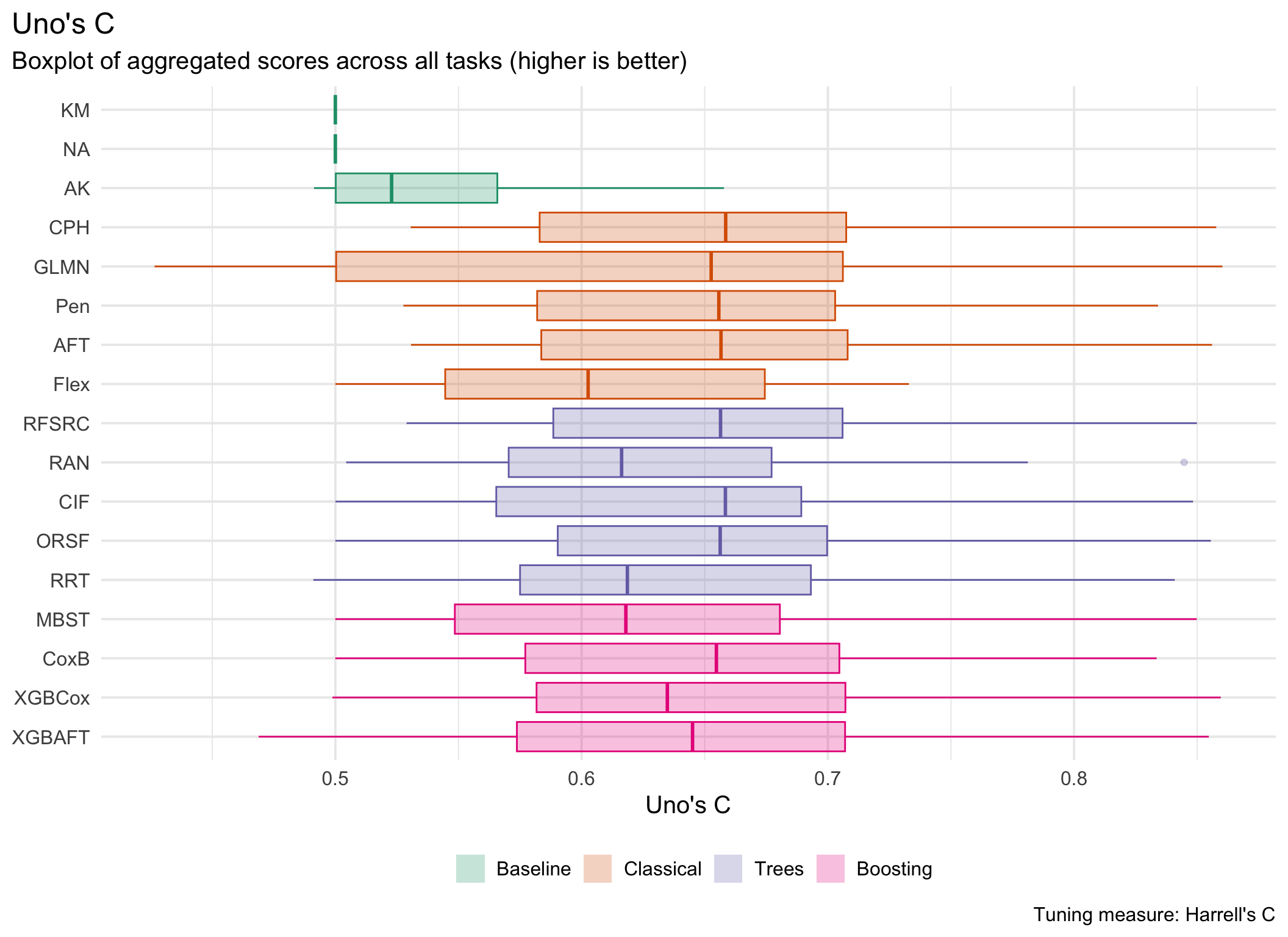
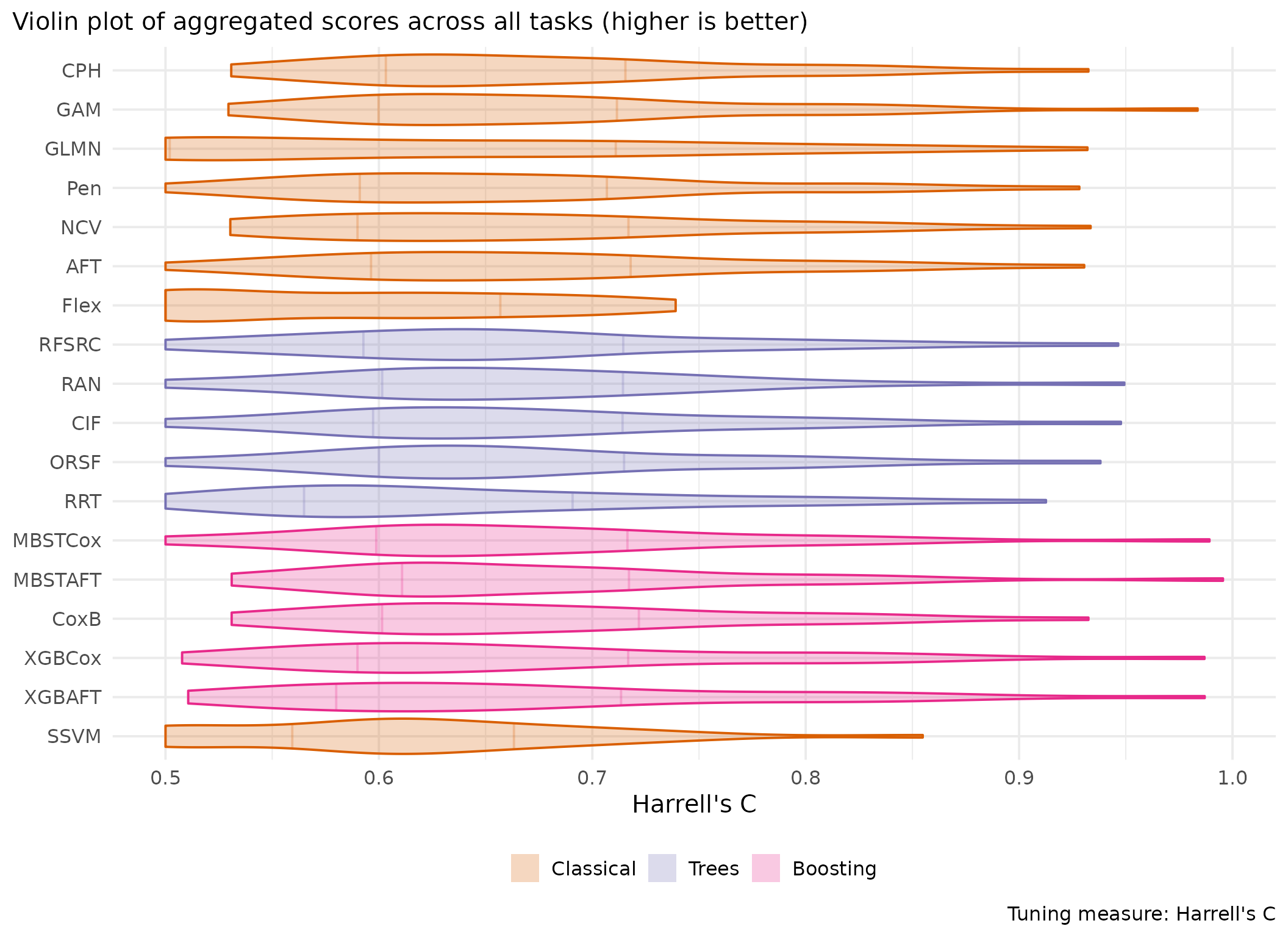
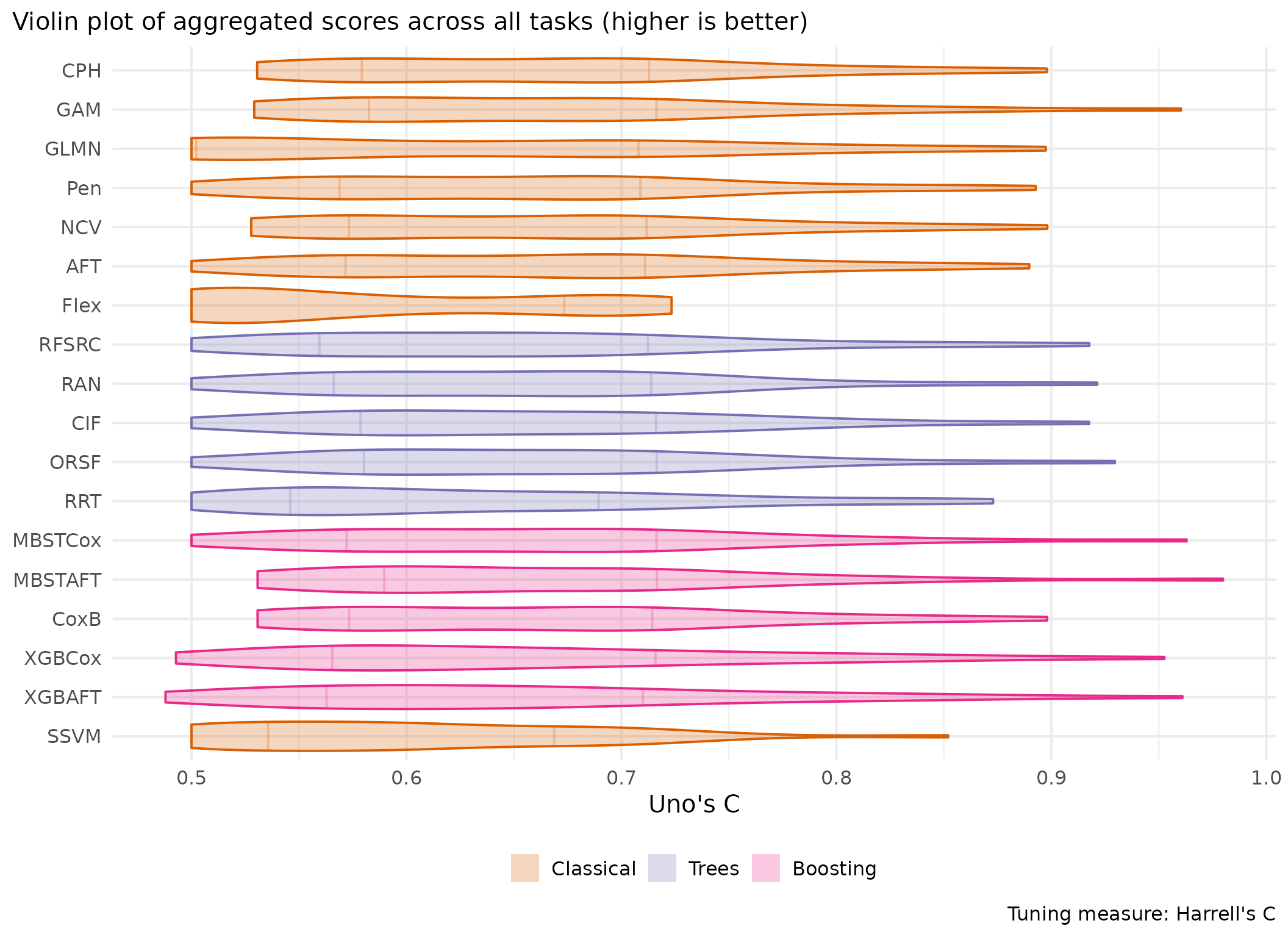
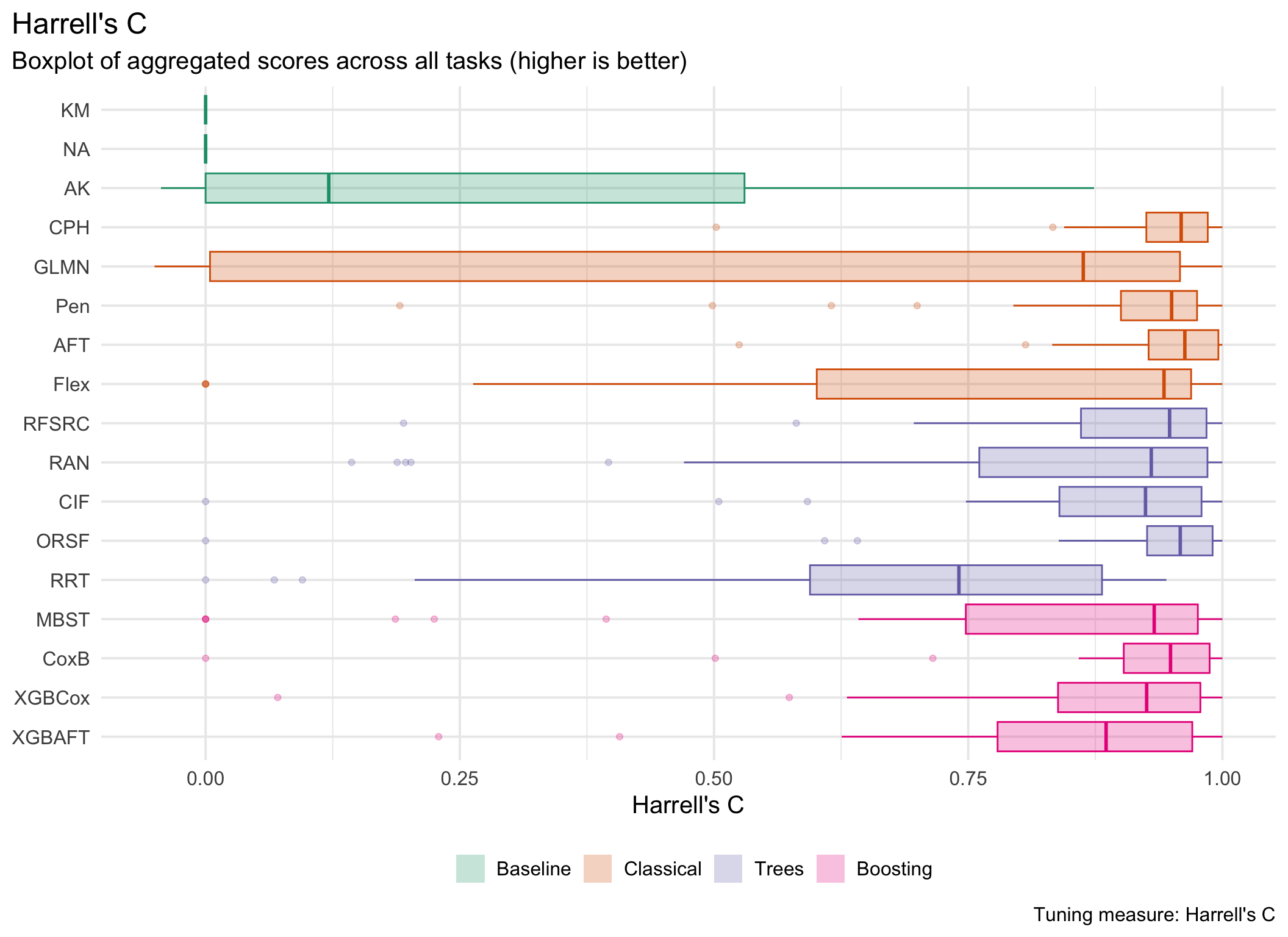
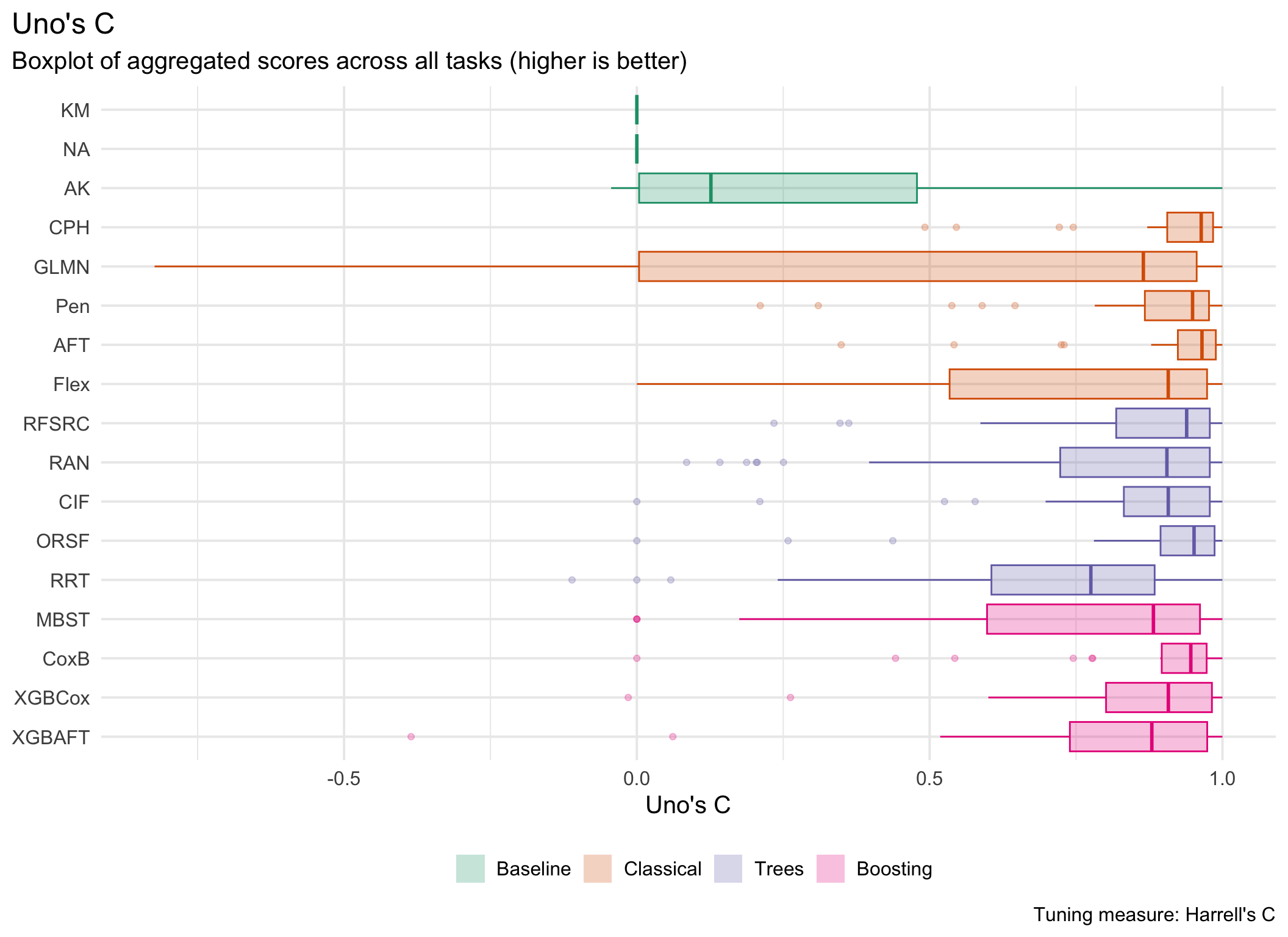
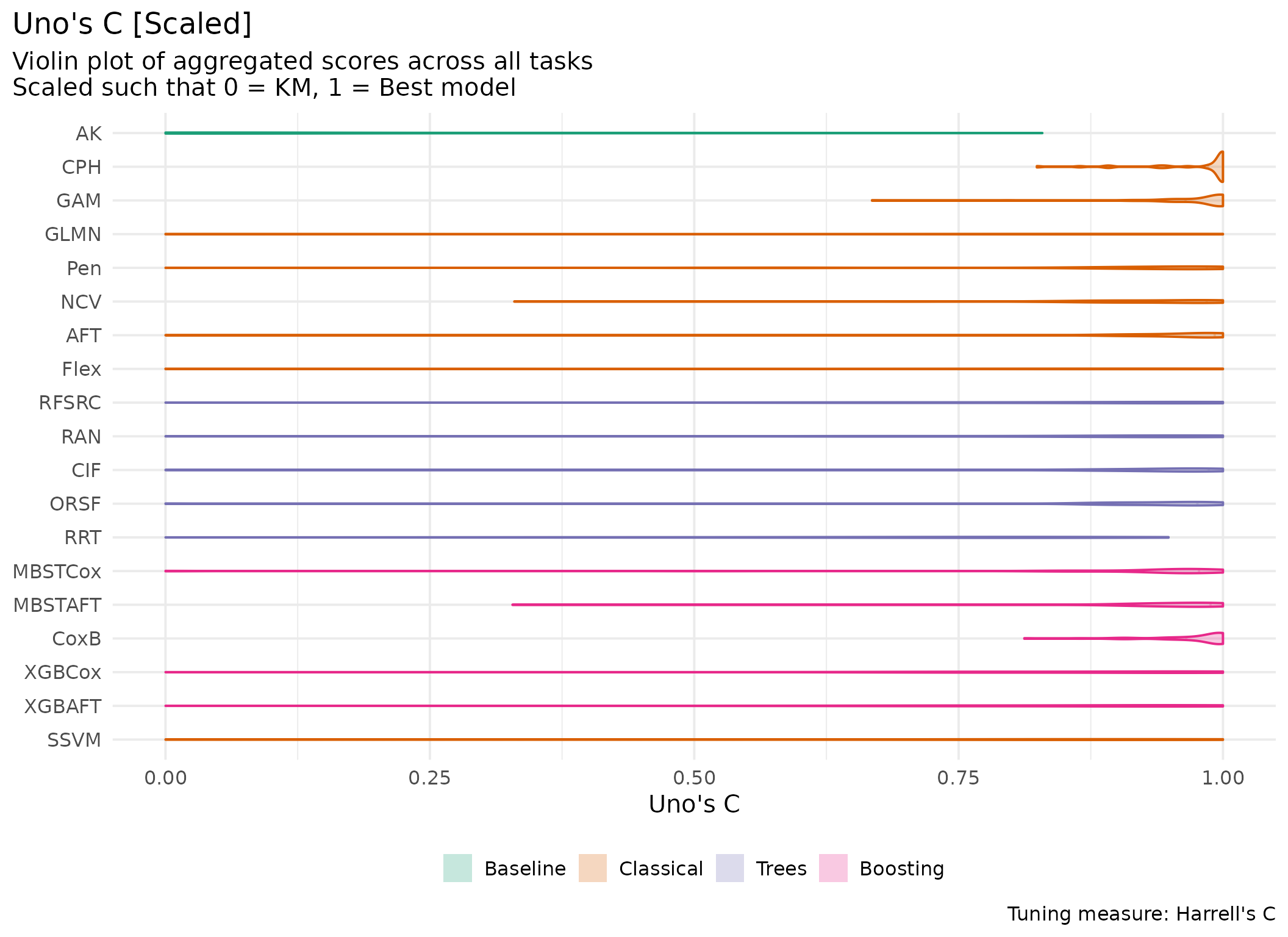
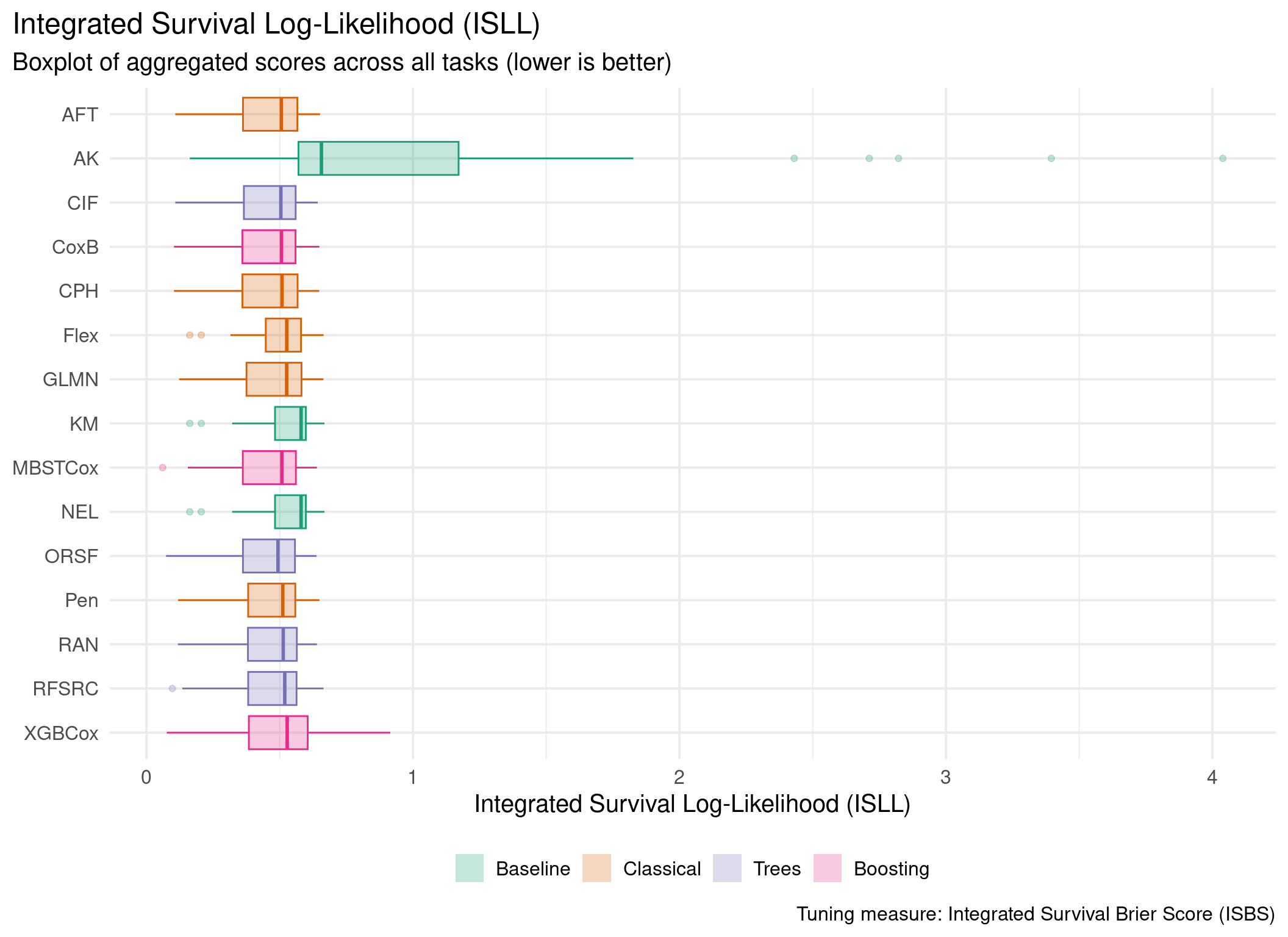
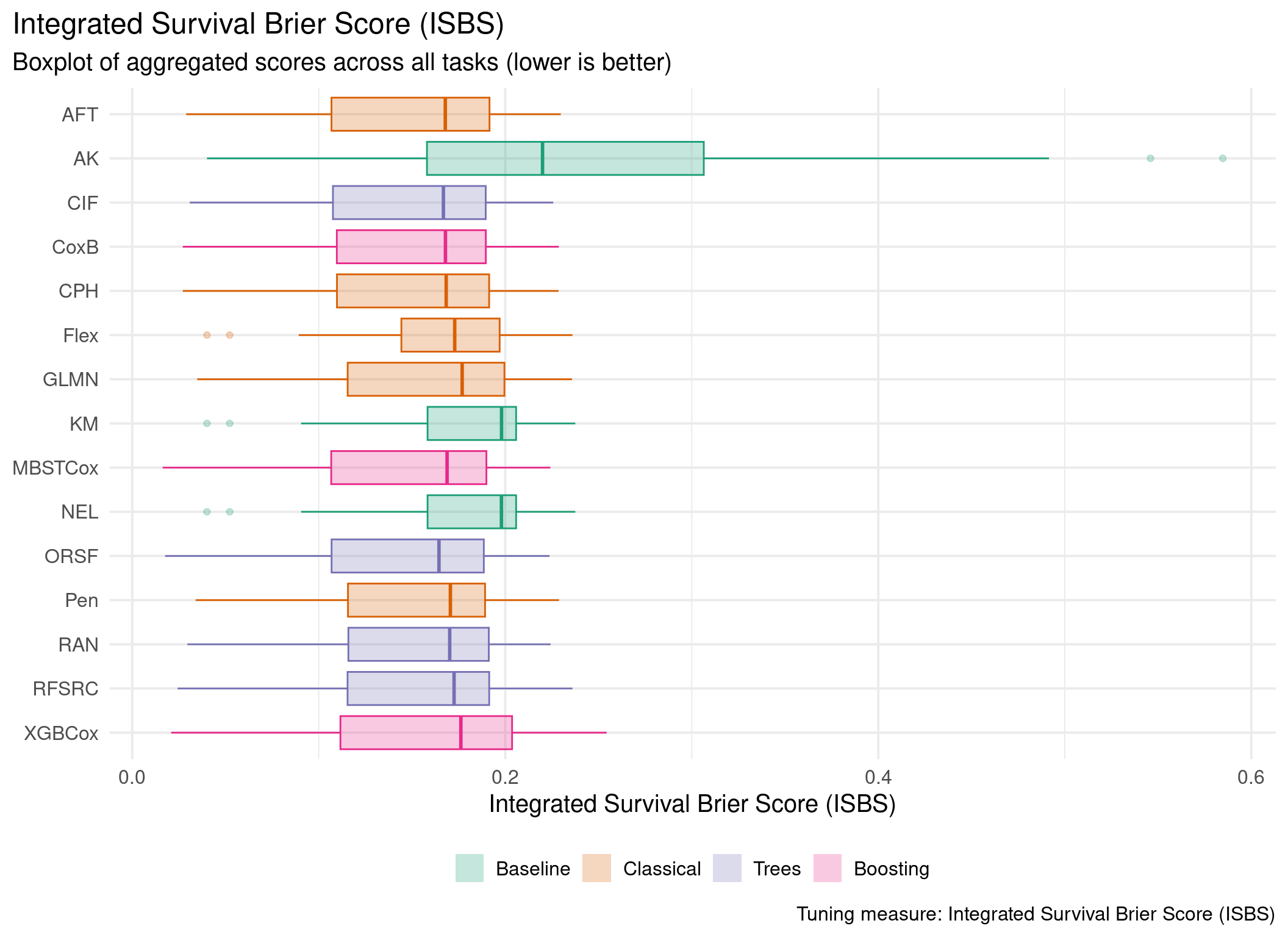
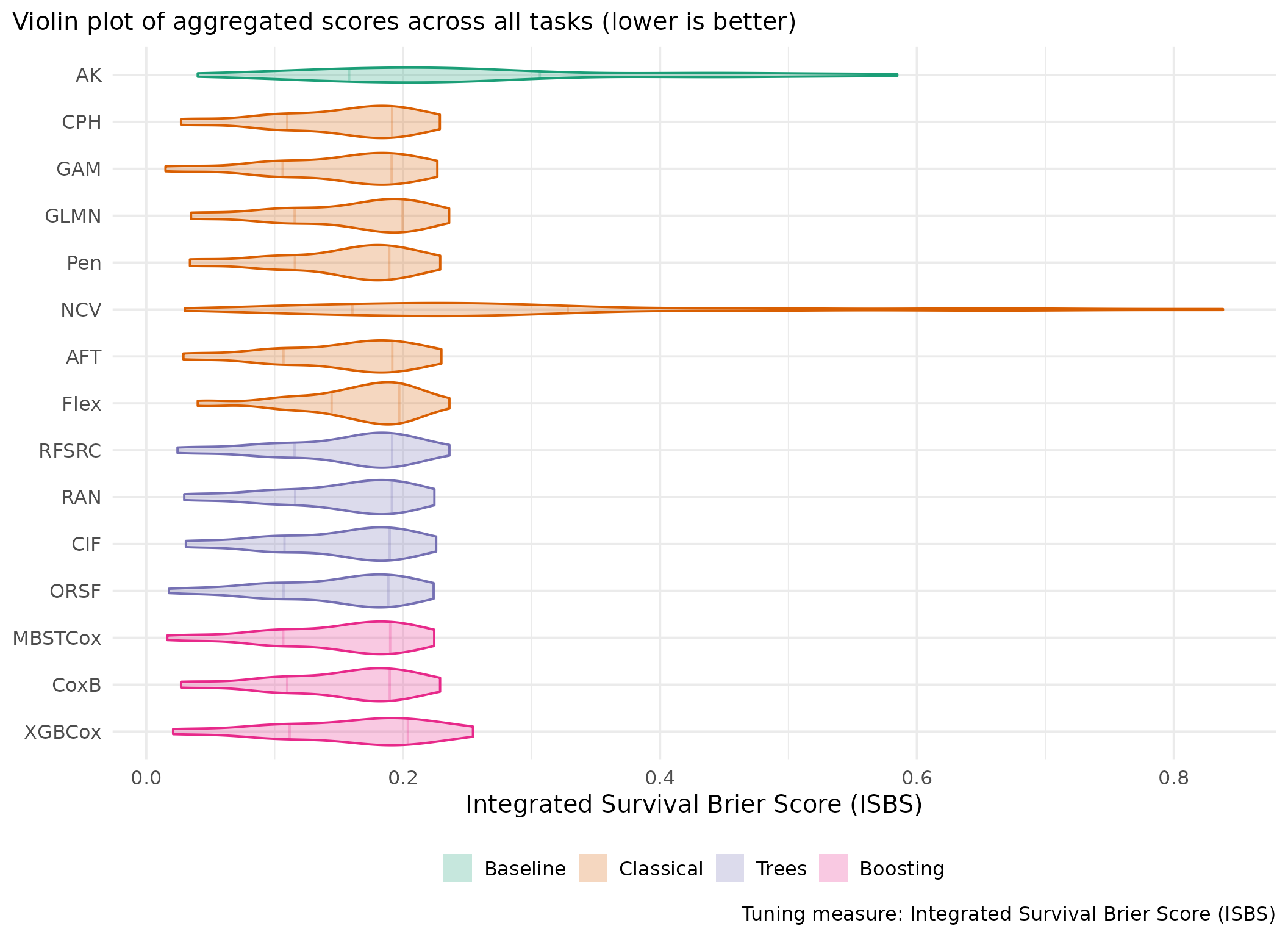
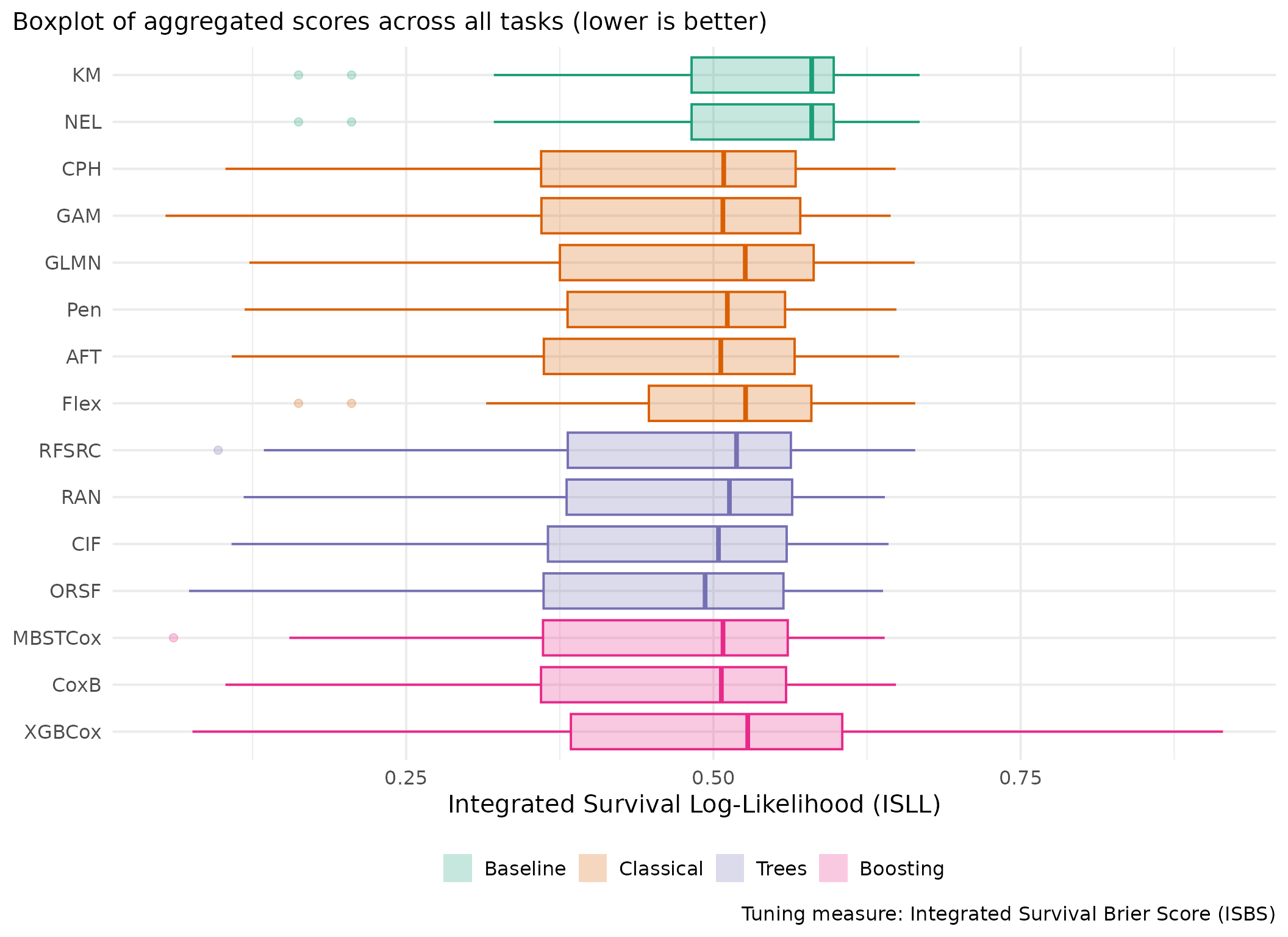
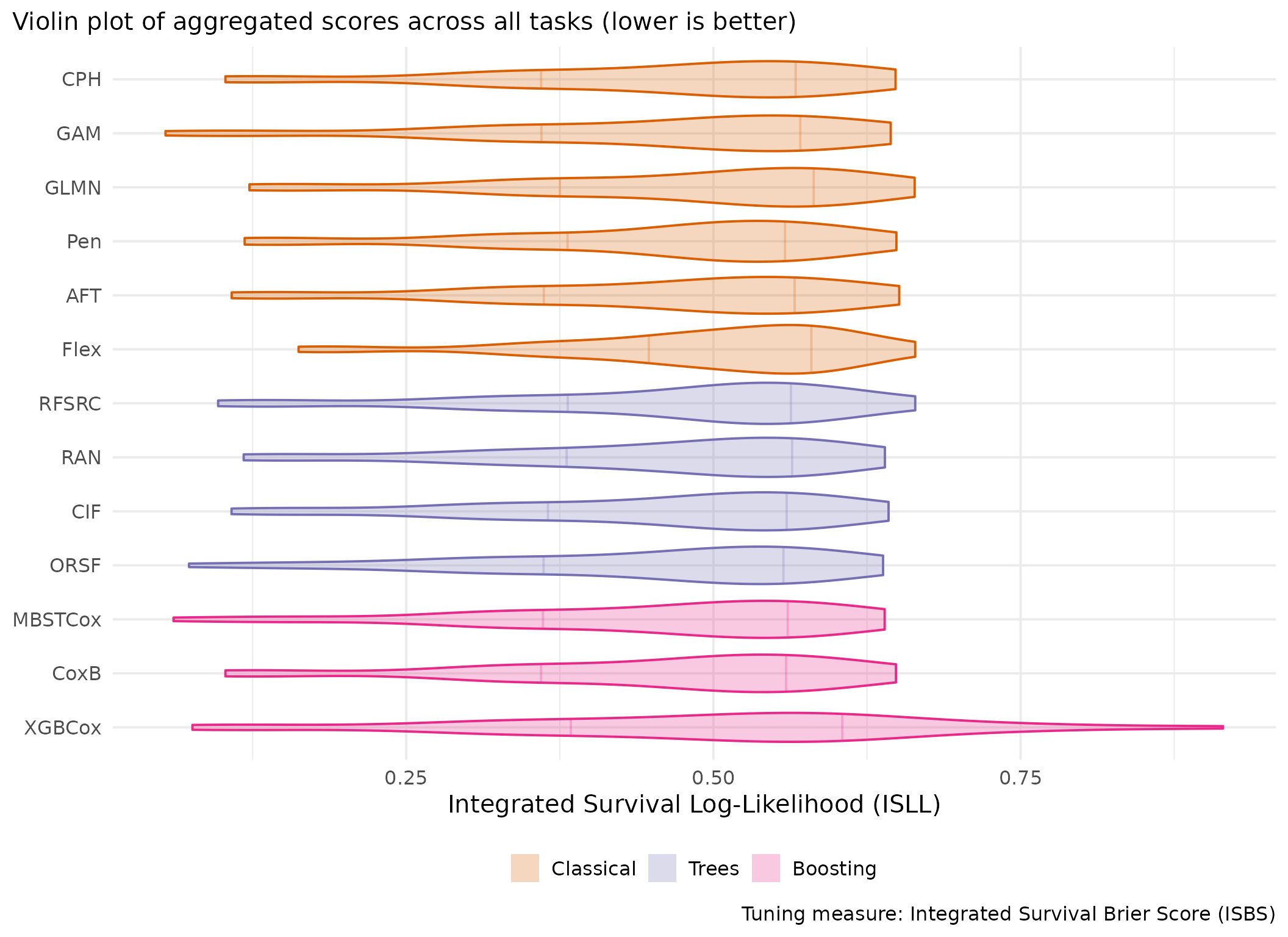
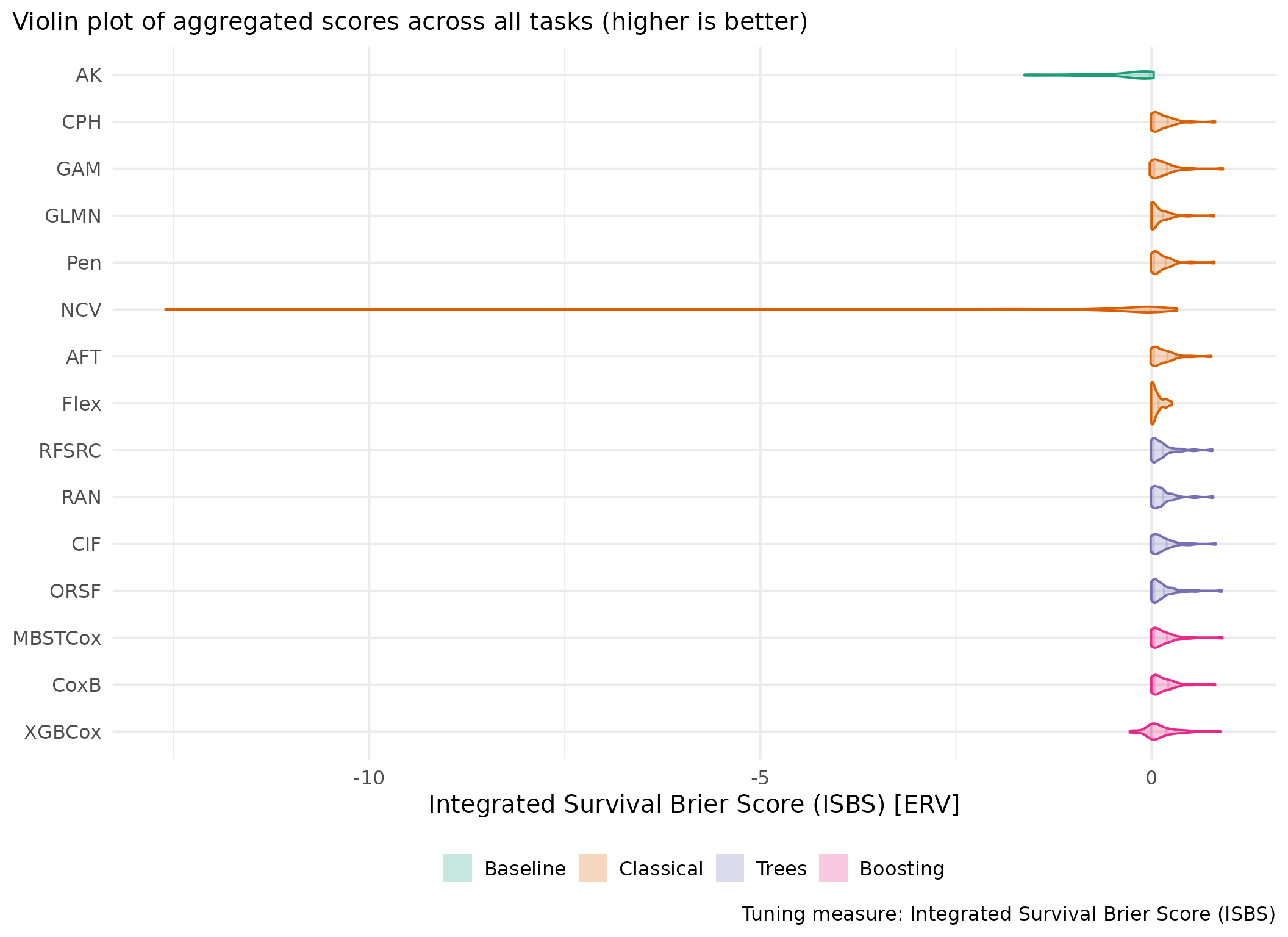
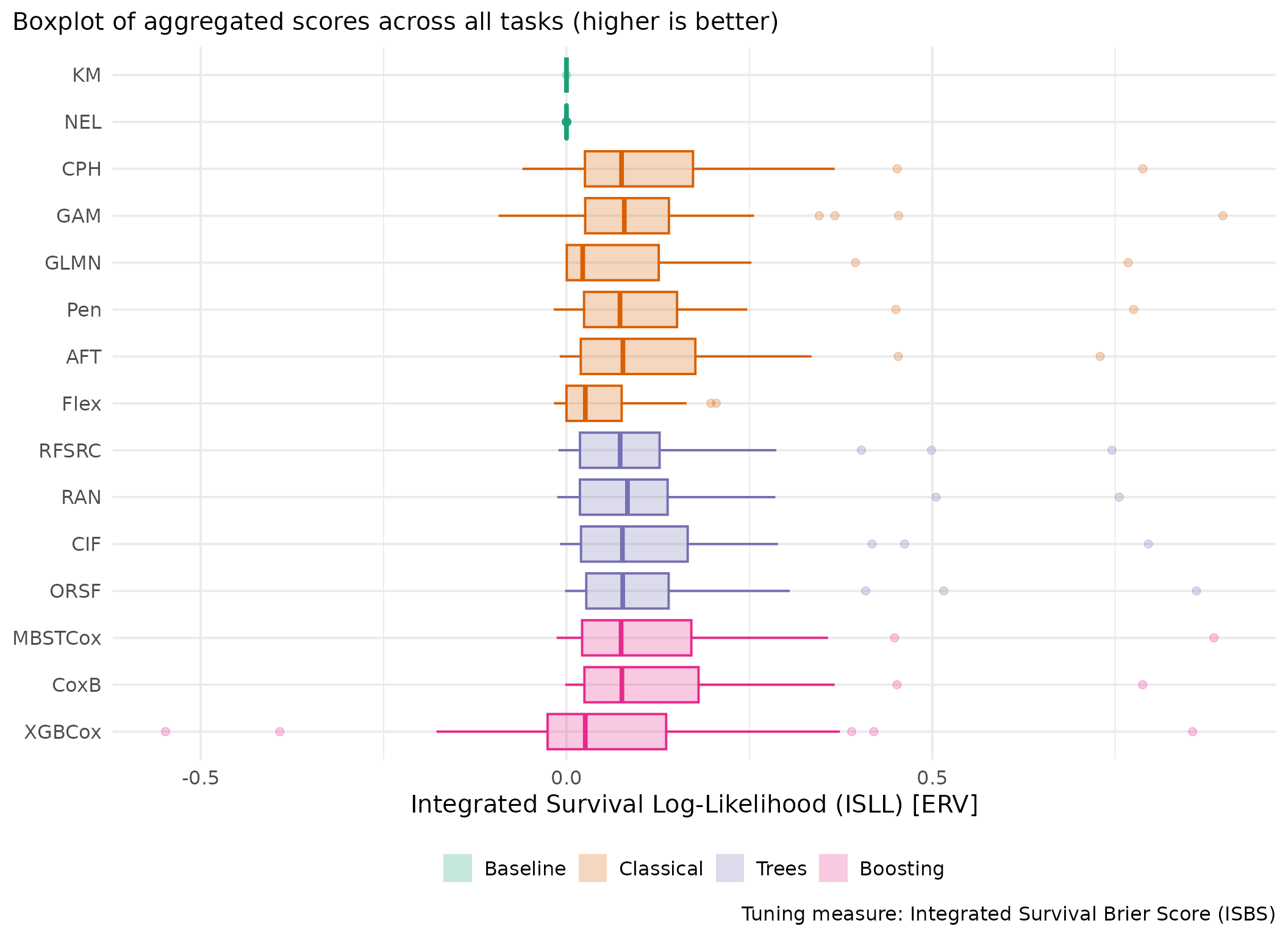
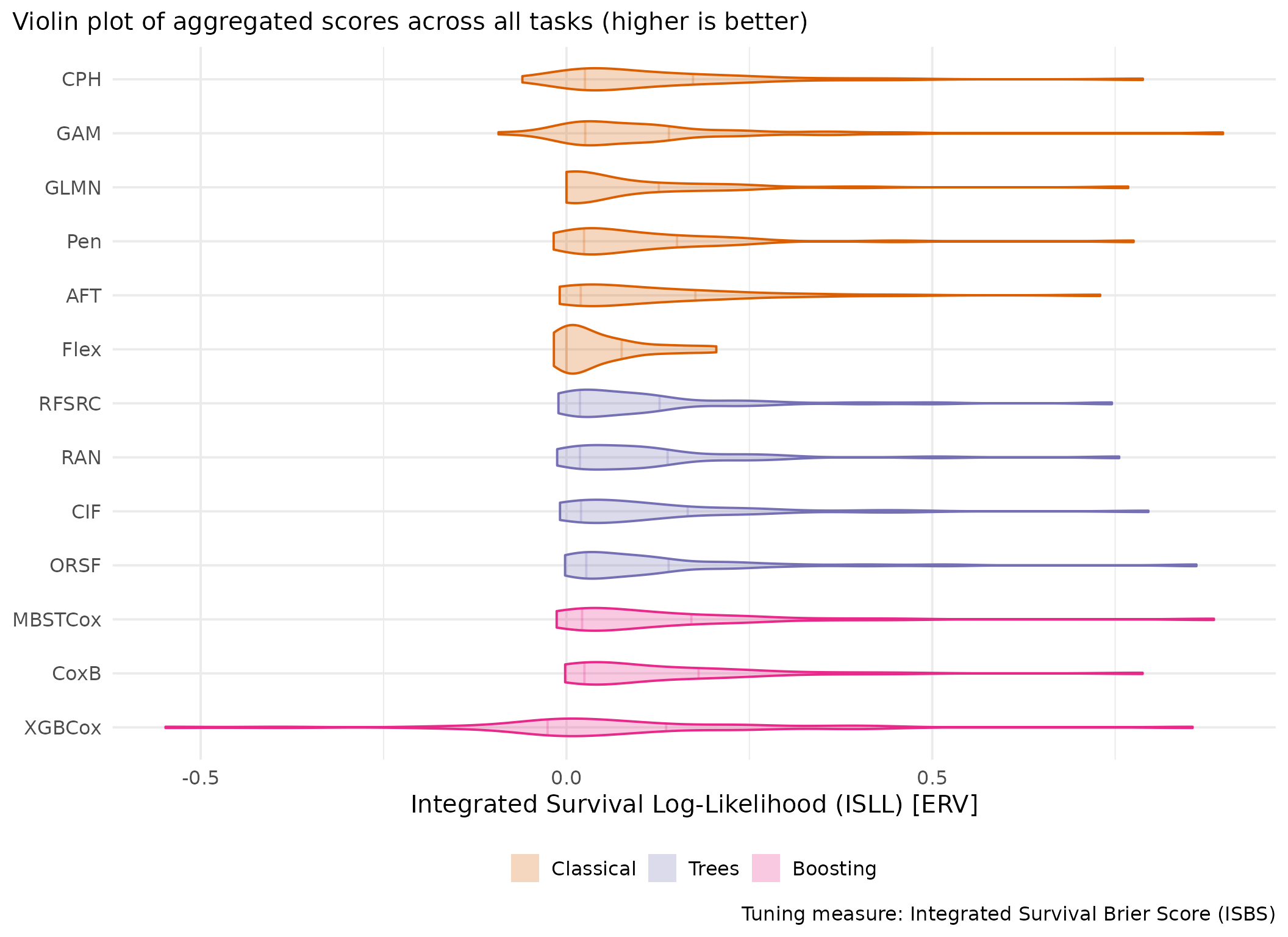
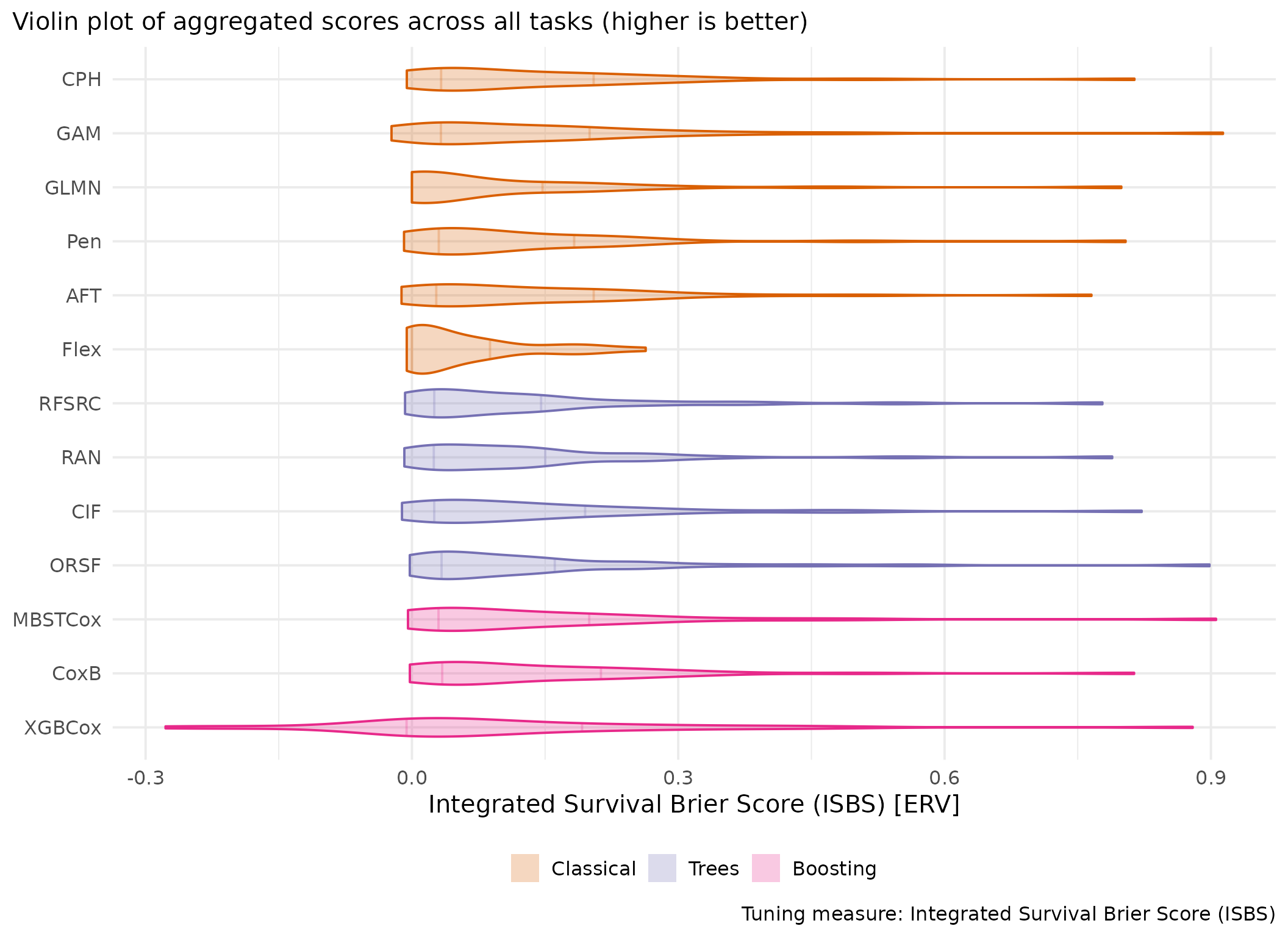
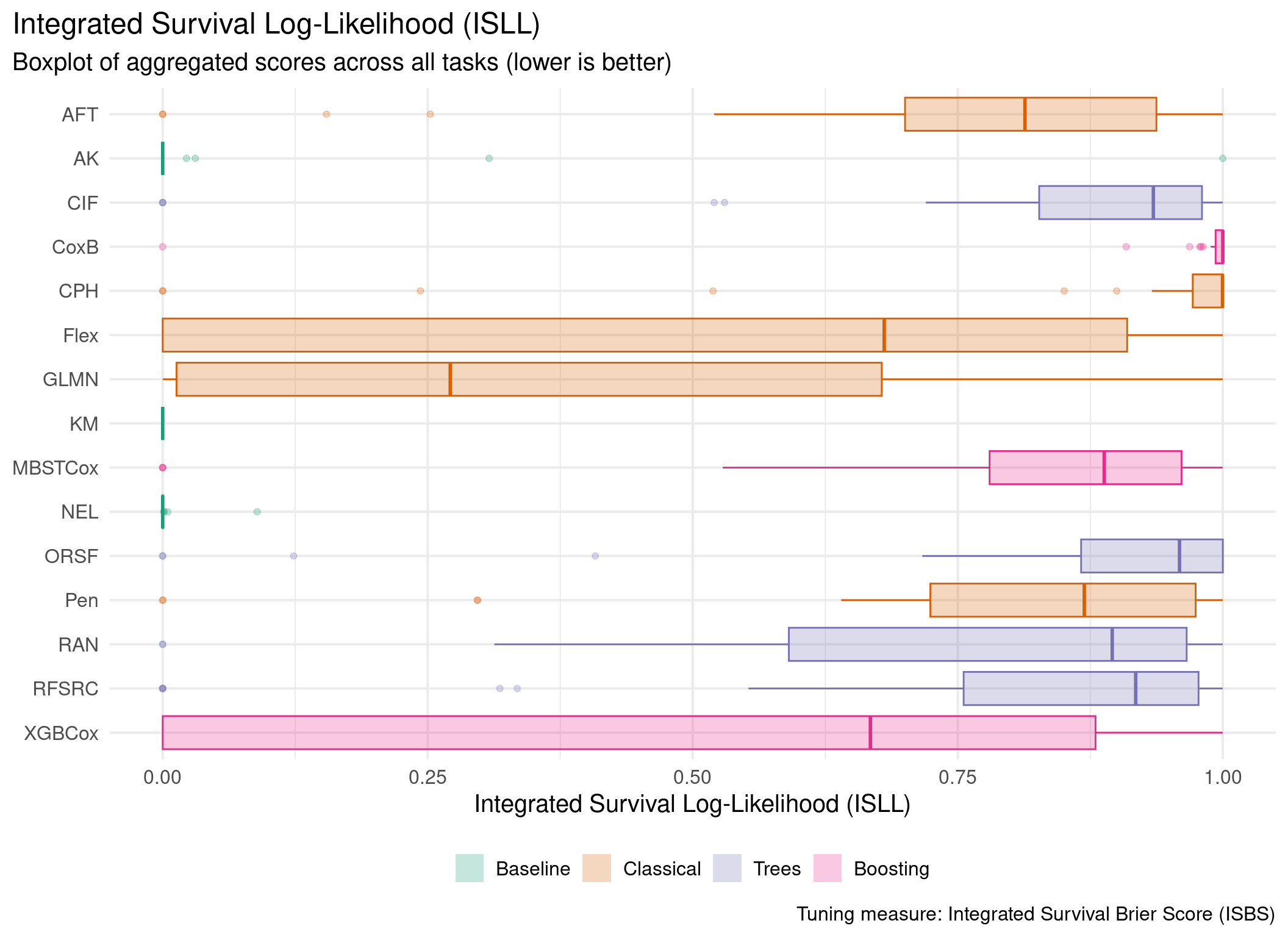
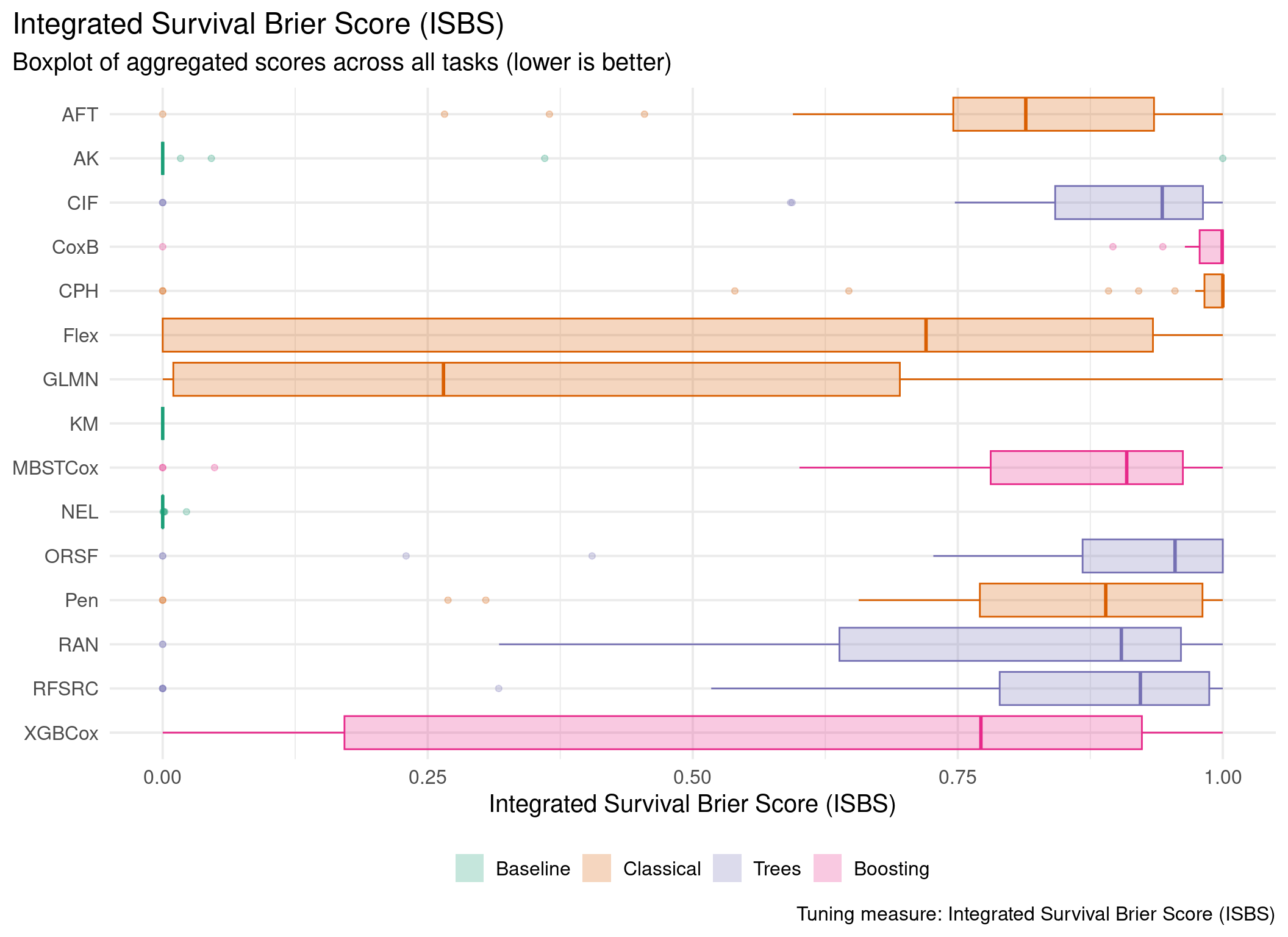
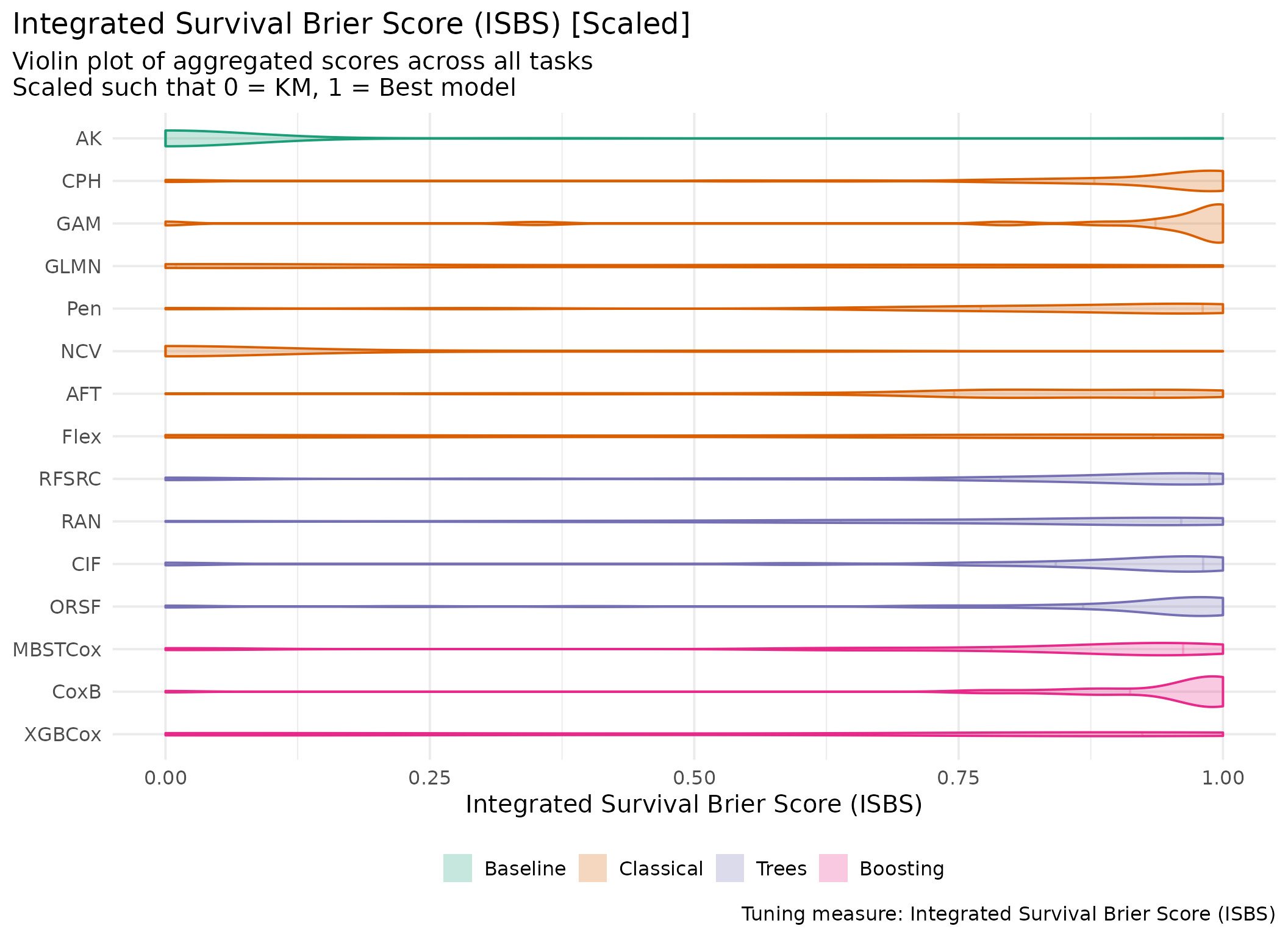
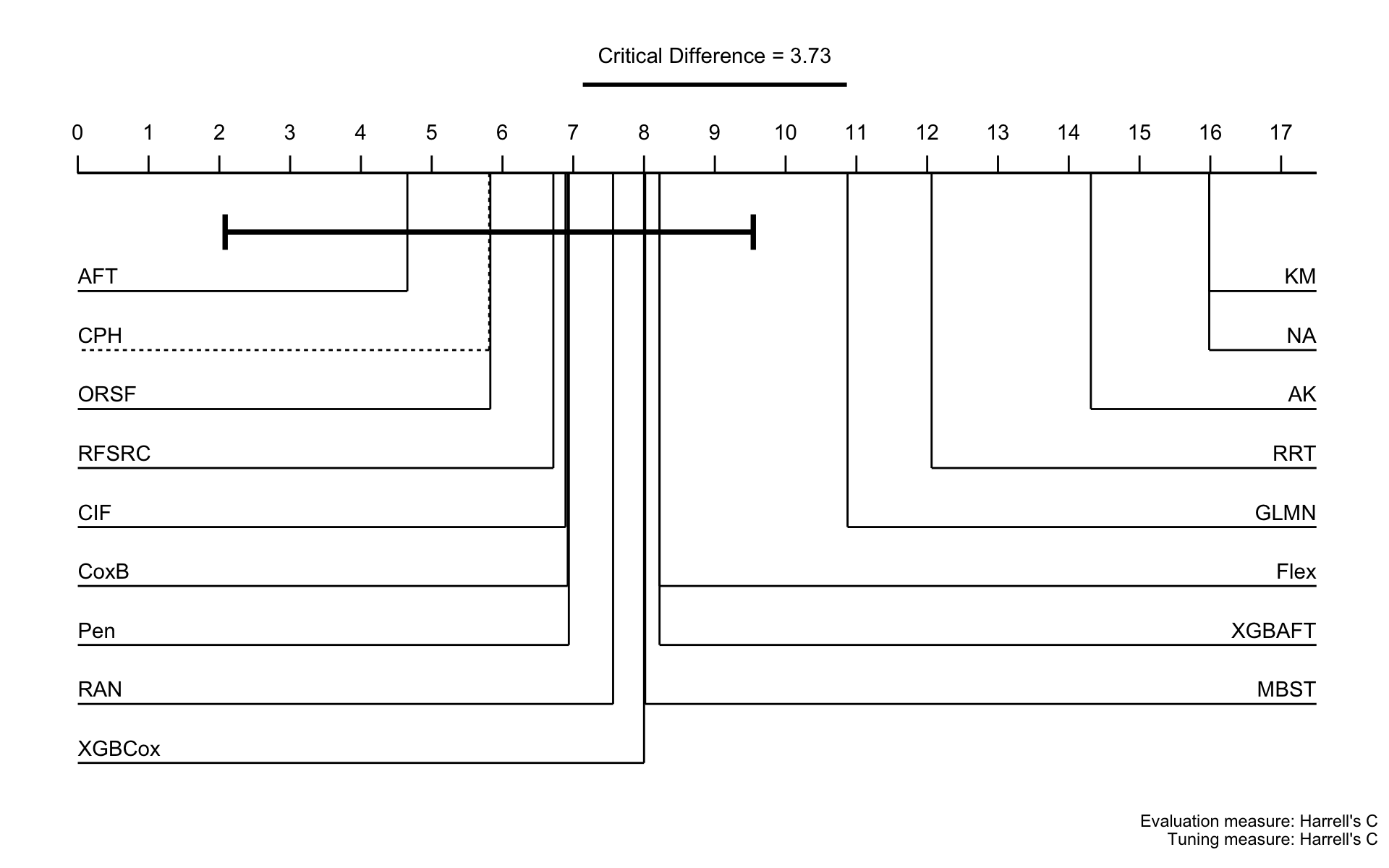
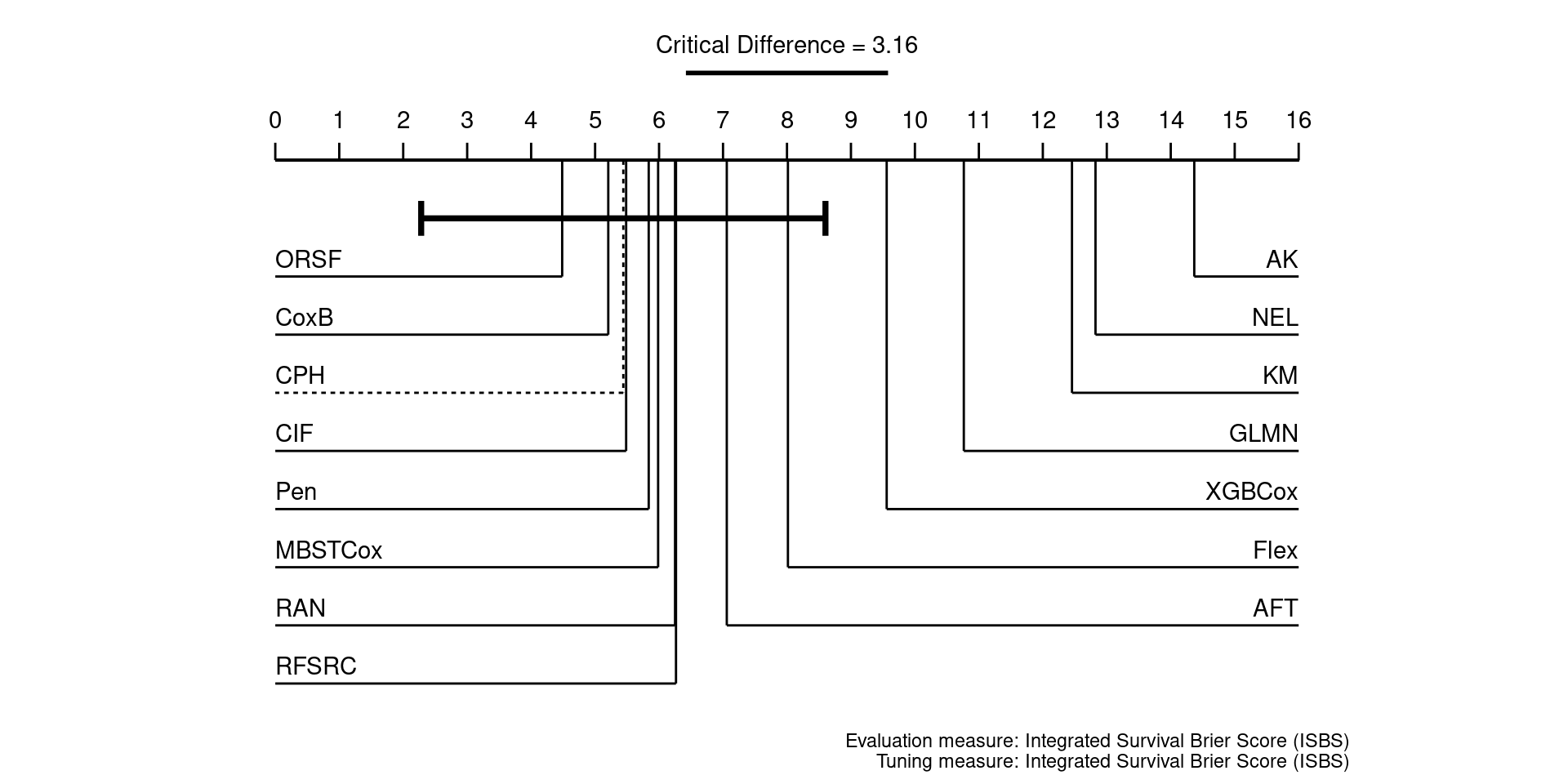
This page presents aggregated benchmark results, including statistical tests and critical difference plots. Results are divided by tuning measure: harrell_c (discrimination) and isbs (proper scoring rule).
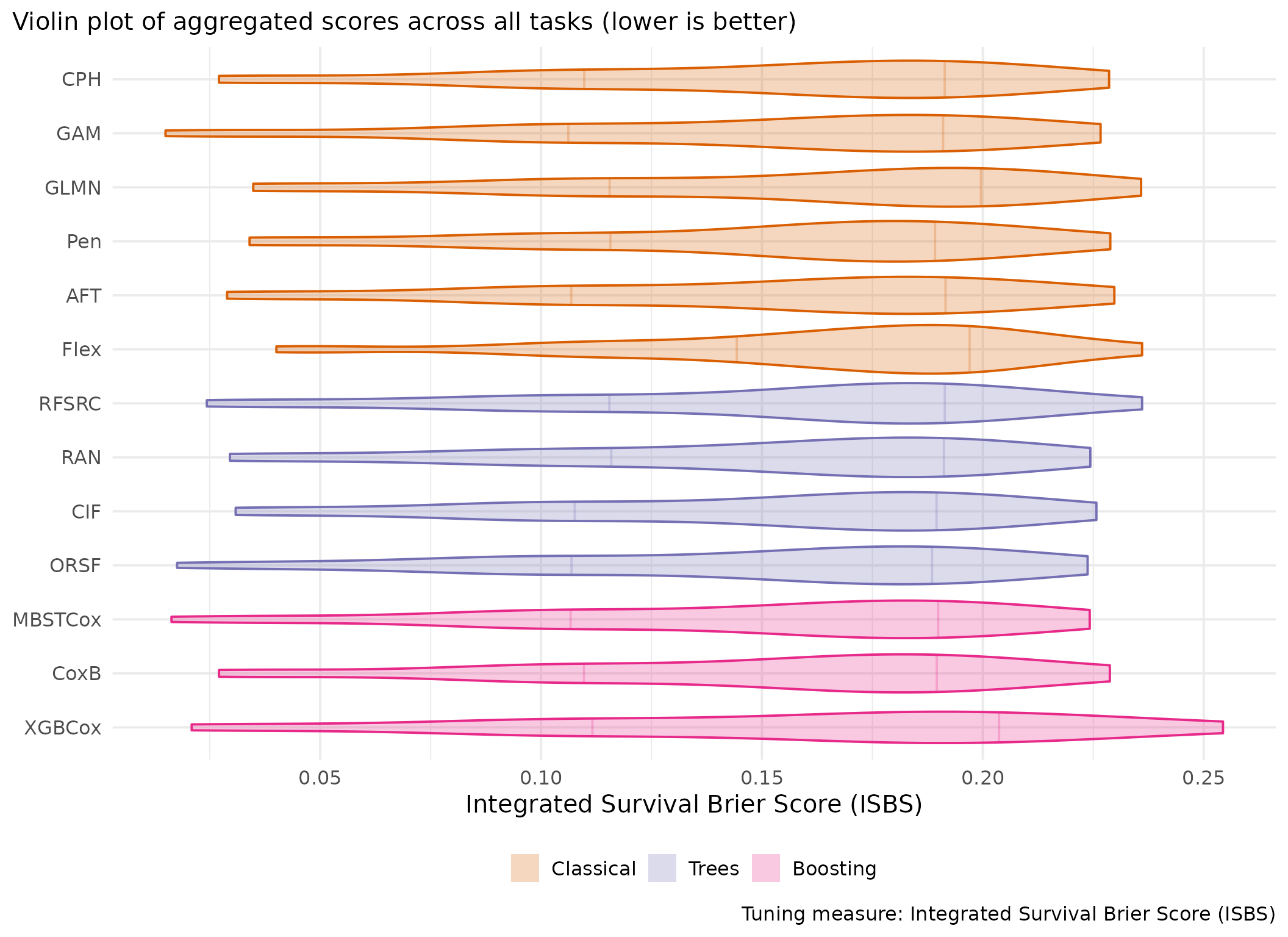
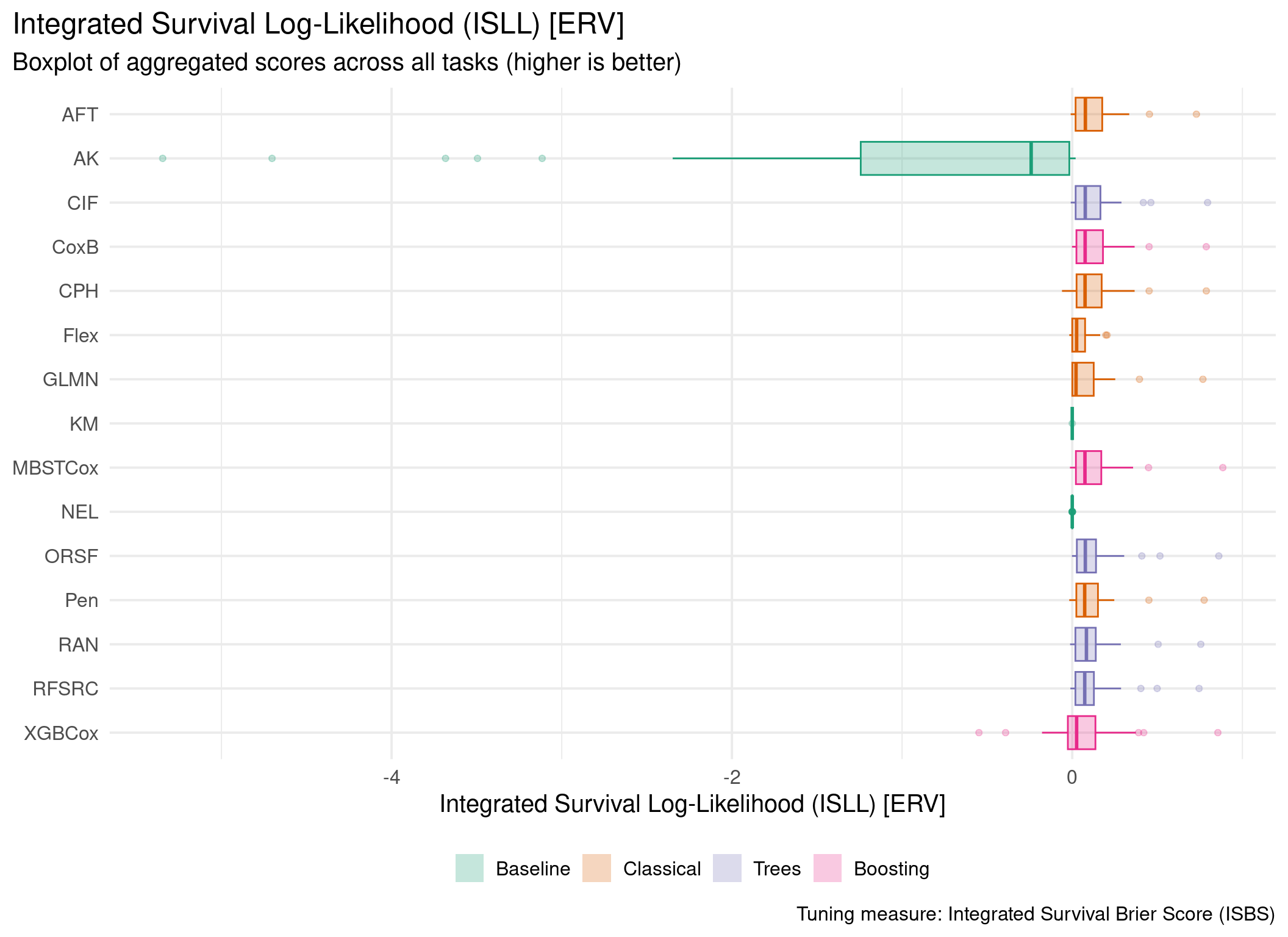
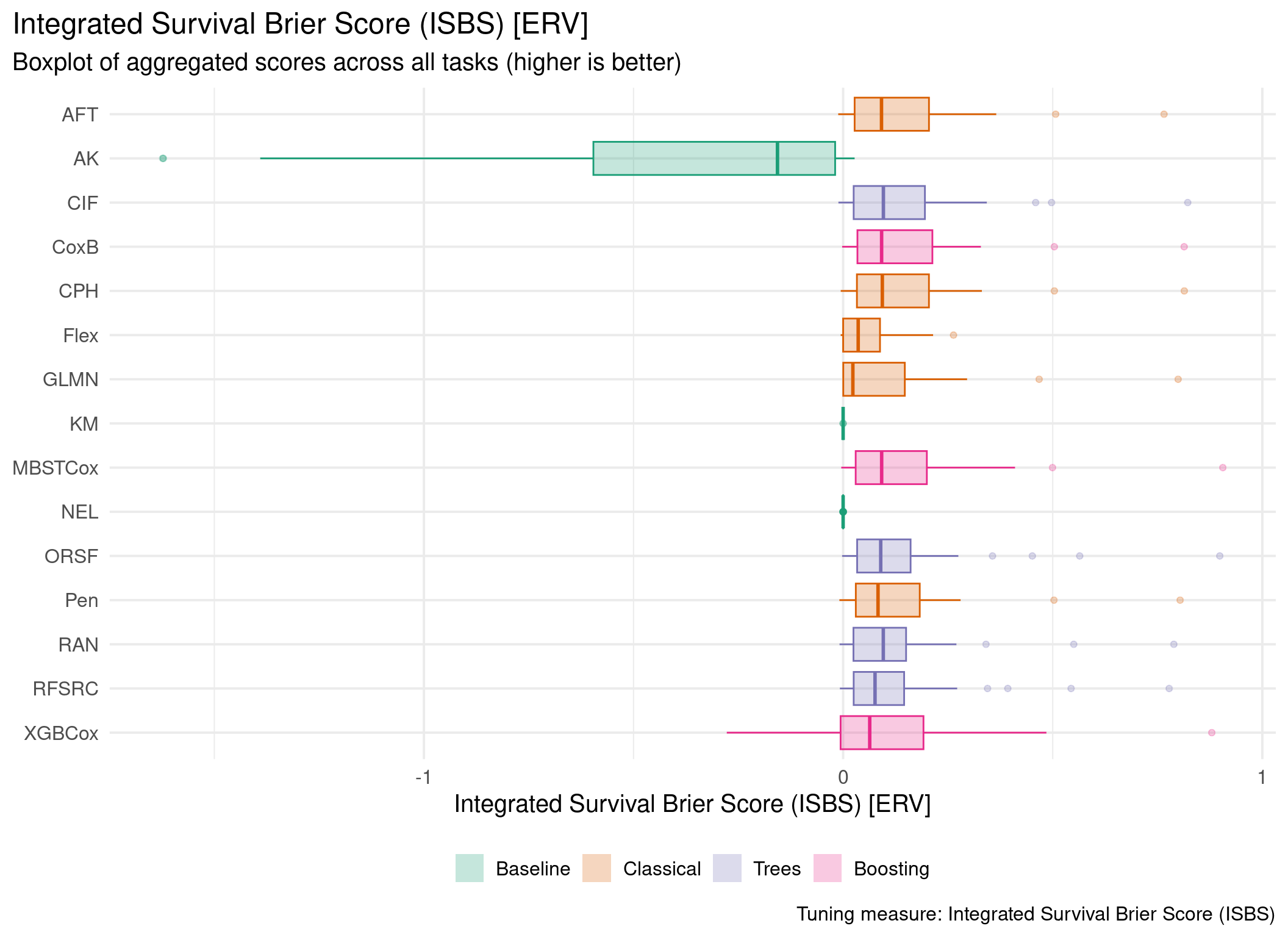
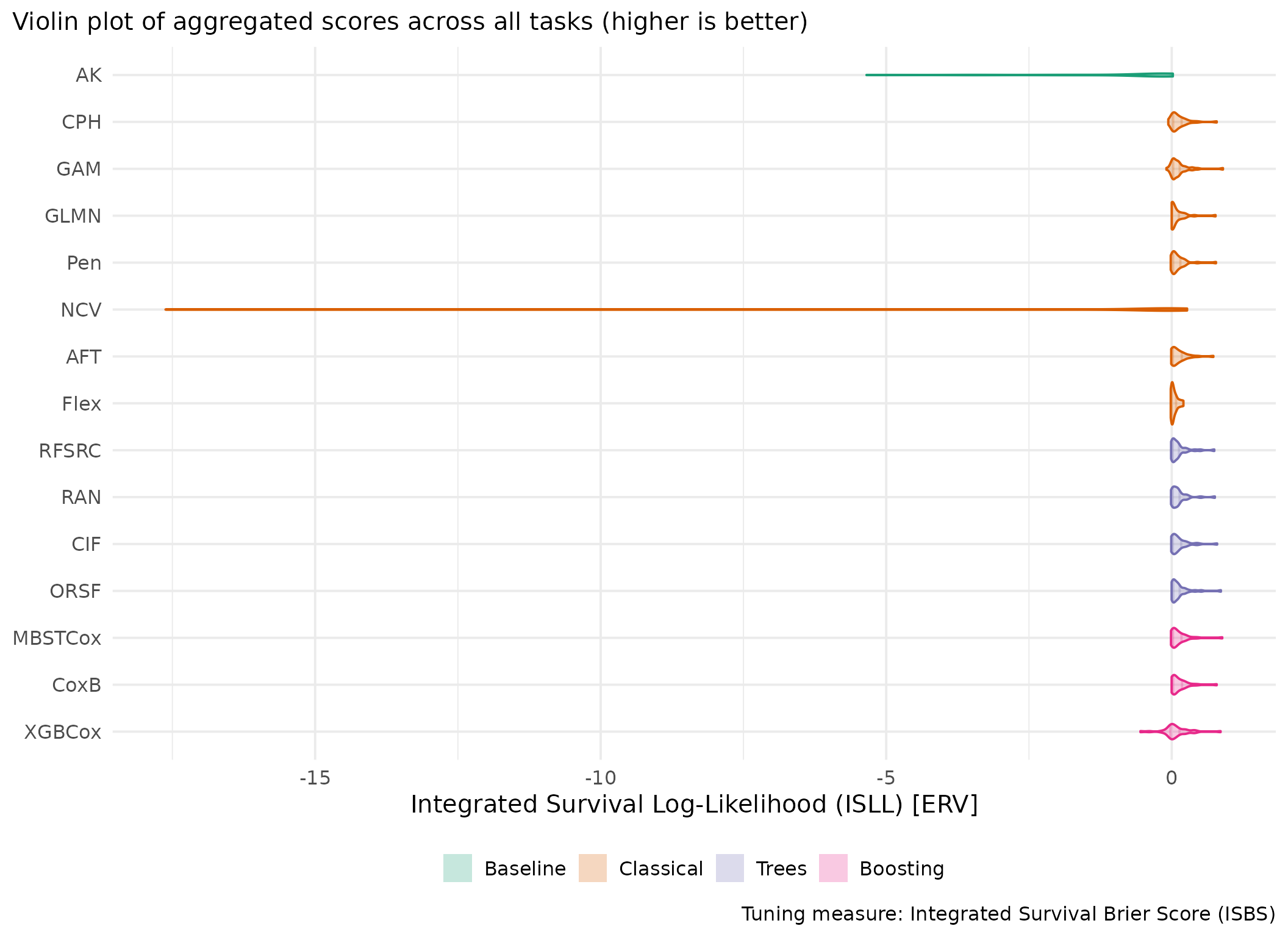
Averaged scores across outer resampling folds for each task and learner.







Calculating p-values for D-Calibration as pchisq(score, 10 - 1, lower.tail = FALSE).
This represents more of a heuristic approach as an insignificant result implies a well-calibrated model, but a significant result does not necessarily imply a poorly calibrated model. Furthermore, there is no multiplicity correction applied due to the generally exploratory nature of the plots.
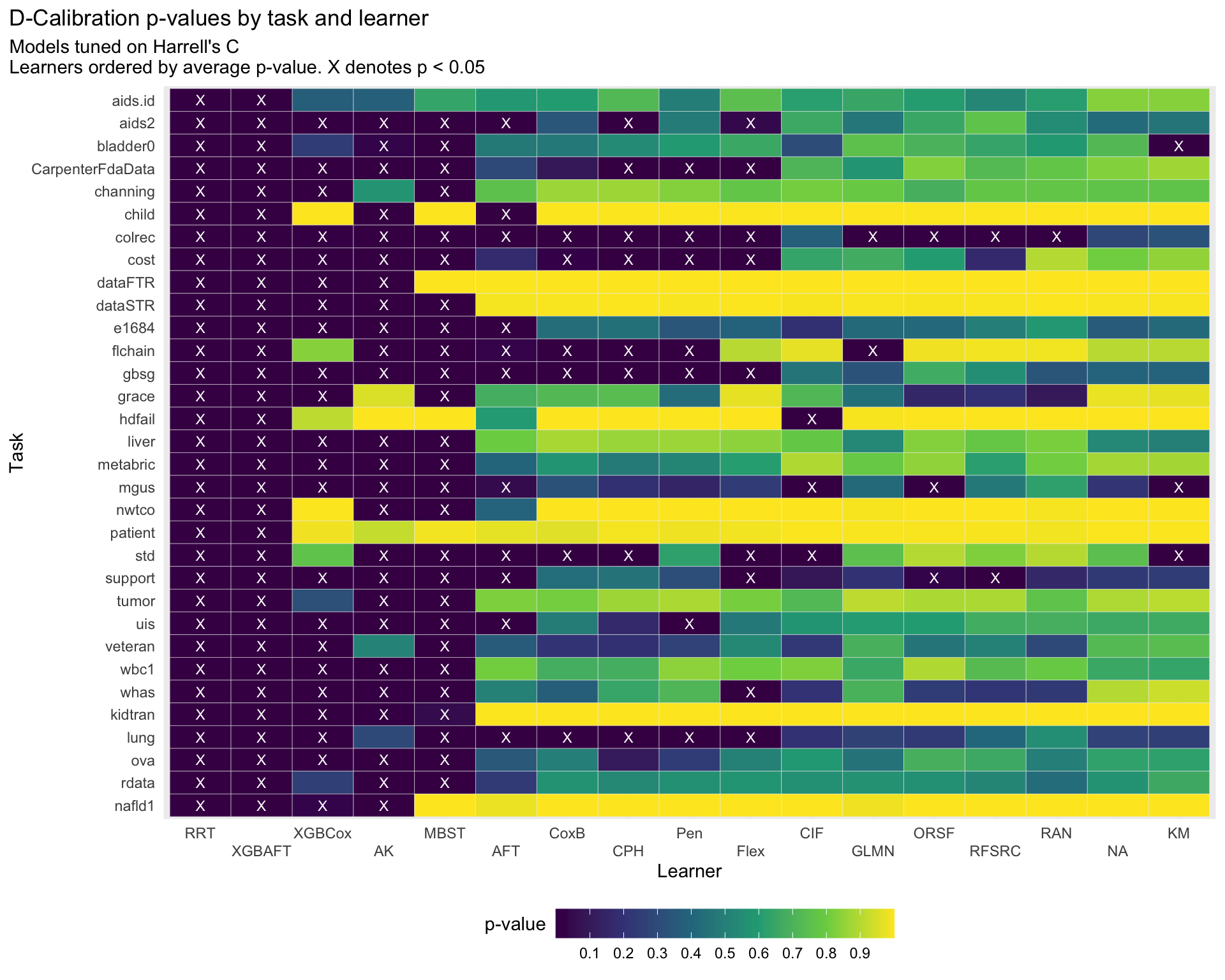
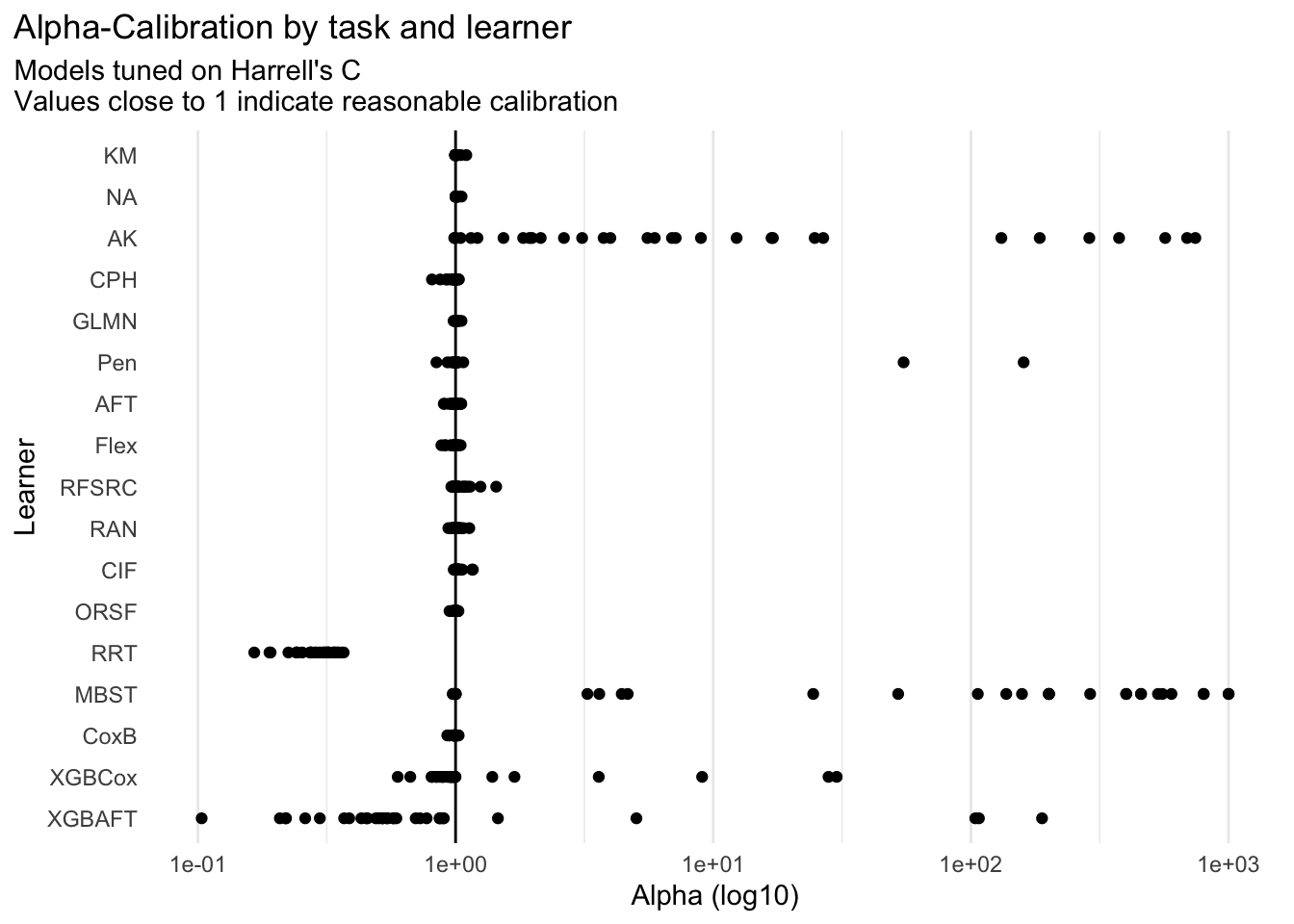
For this measure, calibration is indicated by a score close to 1. The red vertical line marks perfect calibration (alpha = 1).
| X2 | df | p.value | p.adj.value | p.signif | |
|---|---|---|---|---|---|
| harrell_c | 329.508 | 20 | 7.315587e-58 | 0 | *** |
| uno_c | 318.474 | 20 | 1.34273e-55 | 0 | *** |
| X2 | df | p.value | p.adj.value | p.signif | |
|---|---|---|---|---|---|
| isll | 297.9222 | 16 | 6.868346e-54 | 0 | *** |
| isll_erv | 299.362 | 16 | 3.45742e-54 | 0 | *** |
| isbs | 301.7602 | 16 | 1.101756e-54 | 0 | *** |
| isbs_erv | 301.8054 | 16 | 1.078233e-54 | 0 | *** |
| dcalib | 195.6561 | 16 | 5.977296e-33 | 0 | *** |
| alpha_calib | 227.3751 | 16 | 2.192937e-39 | 0 | *** |
Using Cox (CPH) as baseline for comparison, these represent the primary result of the benchmark.
| Column | Type | Description |
|---|---|---|
| Group | fct |
Model / learner group, one of “Baseline”, “Classical”, “Trees”, “Boosting” |
| Learner | fct |
Model / learner name, e.g. RAN for ranger |
| Task | fct |
Dataset name, e.g. veteran |
| Tuning | chr |
Tuning measure, one of harrell_c, isbs, or harrell_c,isbs for untuned learners or “self-tuners” |
harrell_c, uno_c, isll, isll_erv, isbs, isbs_erv, dcalib, alpha_calib |
dbl |
Evaluation measure score |
| warn | int |
Number of warnings encountered during outer resampling |
| err | int |
Number of errors encountered during outer resampling. Errors indicate failure and the prediction of KM was inserted as fallback |